datanode|explain name node data secondary : Tuguegarao On startup, the NameNode enters a special state called Safemode. Replication of data blocks does not occur when the NameNode is in the Safemode state. The NameNode receives . See more 16 de set. de 2023 · Data: domingo, 17 de setembro de 2023. Horário: 16:00 (de Brasília) Árbitro: Anderson Daronco. VAR: Rafael Traci. Onde assistir ao jogo Flamengo x São .
0 · why datanode is not starting
1 · namenode vs datanode
2 · is datanode safe
3 · explain name node data secondary
4 · datanodes download
5 · datanodes bypass
6 · datanodes account
7 · data node and name
Monster Hunter World - Iceborne / Fitgirl Repacks Ver 15.11.01 / 2022 / Online Fix Help for me and Future users So I have downloaded the "online fix" from the site "online - fix . .
datanode*******Learn about the design and features of HDFS, a distributed file system for big data applications. HDFS consists of a NameNode and DataNodes that manage the file system namespace and data blocks. See moreThe placement of replicas is critical to HDFS reliability and performance. Optimizing replica placement distinguishes HDFS from most . See more
To minimize global bandwidth consumption and read latency, HDFS tries to satisfy a read request from a replica that is closest to the reader. If there exists a replica on the same . See more
On startup, the NameNode enters a special state called Safemode. Replication of data blocks does not occur when the NameNode is in the Safemode state. The NameNode receives . See more
Learn about HDFS, a distributed file system that stores large files and allows streaming data access on commodity hardware. Understand the roles and features of . Finally, the third DataNode writes the data to its local repository. Thus, a DataNode can be receiving data from the previous one in the pipeline and at the same time forwarding data to the next one in .A DataNode is considered dead after a set period without any heartbeats (10.5 minutes by default). Replace a disk on a DataNode host In your CDP Private Cloud Base cluster, .
To perform any of datanode admin operations, there are two steps. Update host-level configuration files to indicate the desired admin states of targeted datanodes. .
A DataNode is considered dead after a set period without any heartbeats (10.5 minutes by default). Remove a DataNode. Before removing a DataNode, ensure that all the .A dataNode is a HDFS process that manage storage attached to the nodes that they run on. The DataNodes are responsible for serving read and write requests from the file . A DataNode stores data in the [HadoopFileSystem]. A functional filesystem has more than one DataNode, with data replicated across them.. On startup, a . DataNode, Hadoop, HDFS, NameNode. What is NameNode. Metadata refers to a small amount of data, and it requires a minimum amount of memory to store. Namenode stores this metadata .
4. Follow these steps and your datanode will start again. Stop dfs. Open hdfs-site.xml. Remove the data.dir and name.dir properties from hdfs-site.xml and .
DataNode, Hadoop, HDFS, NameNode. What is NameNode. Metadata refers to a small amount of data, and it requires a minimum amount of memory to store. Namenode stores this metadata .
4. Follow these steps and your datanode will start again. Stop dfs. Open hdfs-site.xml. Remove the data.dir and name.dir properties from hdfs-site.xml and -format namenode again. Then remove the hadoopdata directory and add the data.dir and name.dir in hdfs-site.xml and again format namenode. Then start dfs again.
DataNode is usually configured with a lot of hard disk space. Because the actual data is stored in the DataNode. Hardware Configuration. Hardware configuration of nodes varies from cluster to cluster and it depends on the usage of the cluster. In Some Hadoop clusters the velocity of data growth is high, in that instance more importance is .
To perform any of datanode admin operations, there are two steps. Update host-level configuration files to indicate the desired admin states of targeted datanodes. There are two supported formats for configuration files. Hostname-only configuration. Each line includes the hostname/ip address for a datanode. That is the default format.With the help of Hadoop Data Node Activity test, administrators can monitor all the activities discussed above on every DataNode. In the process, administrators can rapidly identify overloaded DataNodes, slow DataNodes, those where block verification has failed, and those where caching is sub-optimal. Target of the test : A Hadoop cluster. dfs.datanode.data.dir: Comma separated list of paths on the local filesystem of a DataNode where it should store its blocks. If this is a comma-delimited list of directories, then data will be stored in all named directories, typically on different devices. A DataNode stores data in the [HadoopFileSystem]. A functional filesystem has more than one DataNode, with data replicated across them.. On startup, a DataNode connects to the NameNode; spinning until that service comes up.It then responds to requests from the NameNode for filesystem operations.. Client applications can talk .
A DataNode is considered dead after a set period without any heartbeats (10.5 minutes by default). Replace a disk on a DataNode host In your CDP Private Cloud Base cluster, you can replace faulty disks on the DataNode host. You must stop all the managed services and decommission the DataNode role instance before replacing the faulty disk. Given a datanode of size 96TB, let us consider two disk sizes – 8TB and 16TB. A datanode with 8TB disk would have 12 such disks whereas one with 16TB disk would have 6. We can assume an average read/write throughput of 100MB/sec and spindle speed of 7200 RPM for every disk. The table below summarizes bandwidth and IOPS for .explain name node data secondaryThis DataNode health test checks that the Cloudera Manager Agent on the DataNode host is heart beating correctly and that the process associated with the DataNode role is in the state expected by Cloudera Manager. A failure of this health test may indicate a problem with the DataNode process, a lack of connectivity to the Cloudera Manager Agent . Solved: I added an old server already used as datanode in my cluster. The process get completed, but as soon - 283382
Data Nodes. PDF. In AWS Data Pipeline, a data node defines the location and type of data that a pipeline activity uses as input or output. AWS Data Pipeline supports the following types of data nodes: DynamoDBDataNode. A DynamoDB table that contains data for HiveActivity or EmrActivity to use. SqlDataNode.
To perform any of datanode admin operations, there are two steps. Update host-level configuration files to indicate the desired admin states of targeted datanodes. There are two supported formats for configuration files. Hostname-only configuration. Each line includes the hostname/ip address for a datanode. That is the default format.
After I type the start-all.sh and jps, DataNode doesn't list on the terminal >jps 9529 ResourceManager 9652 NodeManager 9060 NameNode 10108 Jps 9384 SecondaryNameNode according to this answer : Datanode process not running in Hadoop. I try its best solution. bin/stop-all.sh (or stop-dfs.sh and stop-yarn.sh in the 2.x serie)datanode explain name node data secondary jps执行后缺少DataNode的解决办法. 之前,centos6.10里面安装了hadoop2.5.0,伪分布式配置好后,正常工作,后由 hadoop 版本2.5.0,换到hadoop版本2.9.2,将原来2.5.0里的配置复制到2.9.2,原来的环境配置保持不变,使用2.9.2的文件重新格式化namenode后,重新开启hadoop,jps命令 .
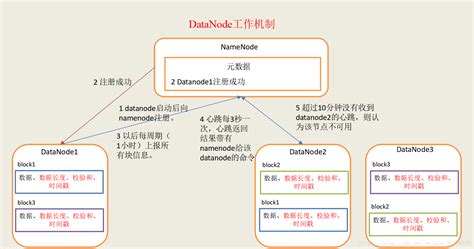
datanode是负责当前节点上的数据的管理,具体目录内容是在初始阶段自动创建的,保存的文件夹位置由配置选项 {dfs.data.dir}决定. 1.2 datanode的作用. datanode以数据块的形式存储HDFS文件. datanode响应HDFS 客户端读写请求. datanode周期性向NameNode汇报心跳信息,数据块信息,缓存数据块信息. 1.3 datanode的多目录配置. datanode也可以配置多个目录,每个目录存储的数据不一样,数据不是副本. (见: .DataNode:在本地文件系统存储文件块数据,以及块数据的校验和。 作用:存储实际的数据块;执行数据块的读/写操作。 Checkpoints: 作用就是合并fsimage和Edits文件,然后生成最新的fsimage。datanode Datanode是HDFS文件系统的工作节点,它们根据客户端或者是namenode的调度进行存储和检索数据,并且定期向namenode发送它们所存储的块(block)的列表。 NameNode上并不永久保存哪个DataNode上有哪些数据块的信息,而是通过DataNode启动时的上报来更新NameNode上的映射表。 同理 DataNode 节点上的数据损坏了,却没有发现,是否也很危险,那么如何解决呢? 如下是 DataNode 节点保证数据完整性的方法。 (1)当 DataNode 读取 Block 的时候,它会计算 CheckSum。 HDFS exposes a file system namespace and allows user data to be stored in files. Internally, a file is split into one or more blocks and these blocks are stored in a set of DataNodes. The NameNode executes file system namespace operations like opening, closing, and renaming files and directories.
DataNode详解. DataNode在HDFS中真正存储数据。 首先解释块(block)的概念: DataNode在存储数据的时候是按照block为单位读写数据的。block是hdfs读写数据的基本单位。 假设文件大小是100GB,从字节位置0开始,每128MB字节划分为一个block,依此类推,可以划分出很多的block。
Overview. HDFS is the primary distributed storage used by Hadoop applications. A HDFS cluster primarily consists of a NameNode that manages the file system metadata and DataNodes that store the actual data. The HDFS Architecture Guide describes HDFS in detail.
Assistir The Rookie online: streaming, compre ou alugue. Você pode assistir "The Rookie" no Paramount Plus, Oi Play, Paramount+ Amazon Channel, Paramount Plus Apple TV Channel , NOW, Globoplay em Stream legalmente.
datanode|explain name node data secondary